So mancher möchte die immensen Datenmengen aus seiner Produktion nutzen und in seinem Unternehmen ein KI-System testen. Nur: Welche Anwendungen wären aussichtsreich? Wie kommt man an die passenden Datensätze? Antworten geben Aachener Wissenschaftler.
Juli 2019 – Steigende Rechenleistungen und bessere Datengrundlagen bei gleichzeitig sinkenden Kosten für Rechen- und Speicherkapazitäten stellen die Basis für den Einsatz von Machine Learning (ML) in der Produktion dar. Dies führt dazu, dass Verfahren des ML vermehrt in der Produktion Anwendung finden. Sie können eingesetzt werden, um Systeme der Künstlichen Intelligenz (KI bzw. Artificial Intelligence, AI) zu trainieren, von denen sich die Mehrzahl der Unternehmen Steigerungen in ihrer Produktivität erhofft. Doch einfach loslegen geht nicht, denn zuallererst einmal müssen aussichtsreiche Anwendungsgebiete und die damit verbundenen Lernaufgaben (Learning Tasks) für KI-Systeme in der eigenen Produktion identifiziert werden. Nicht zuletzt müssen passende Datensätze gefunden werden.
Neue Übersicht der Anwendungsgebiete erleichtert Auswahl
Die Entscheidung, ML in der Produktion anzuwenden, wird aus unterschiedlichsten Gründen und von verschiedenen Verantwortlichen getroffen. In manchen Fällen ist es der Prozessverantwortliche, der ein konkretes Problem lösen möchte. In anderen ist es die Managementebene, die den Einsatz von ML erproben will.
Voraussetzung ist in jedem Fall die Wahl des richtigen Anwendungsgebiets im Unternehmen. Studien, die einen Überblick über mögliche Anwendungsgebiete aufzeigen, betrachten aber häufig nur Teilaspekte moderner Produktionsstätten. Eine hohe Abstraktionsebene oder mangelnde Aktualität führen dazu, dass sich diese Studien nur eingeschränkt zur Identifizierung der unternehmenseigenen Problemstellungen eignen.
Um eine Grundlage für die Auswahl eines Use Cases bereitzustellen, wurden am Fraunhofer IPT die in Abbildung 1 dargestellten Anwendungsgebiete identifiziert. Diese basieren auf eigenen Studien sowie Erfahrungen aus Industrie- und Forschungsprojekten. Die Anwendungsgebiete lassen sich in drei Cluster einteilen: Prozess, Maschinen & Anlagen sowie Produkt. Durch die Übersicht lassen sich neue Projekte identifizieren und Ansatzpunkte für die Datensammlung in der Produktion finden.
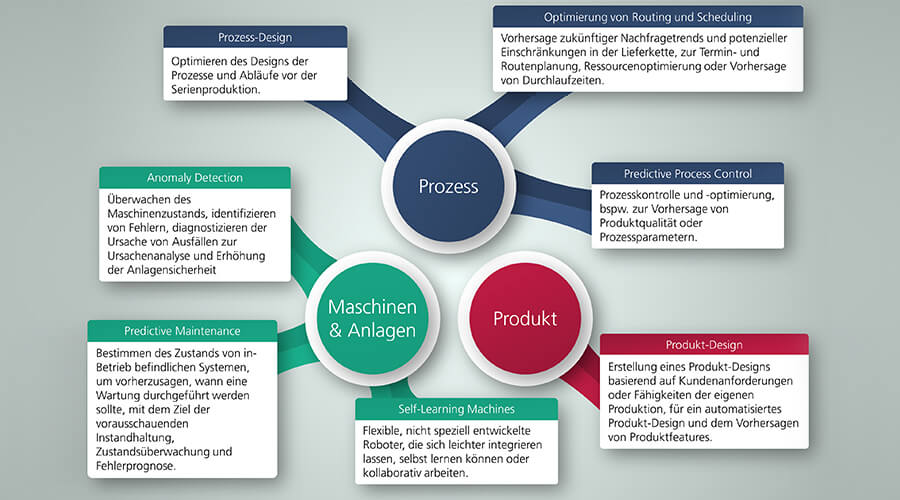
Abbildung 1: Übersicht der Anwendungsgebiete Prozess, Maschinen & Anlagen sowie Produkt. Hierunter sind Anwendungsgebiete in der Produktion verortet und mit Anwendungen umschrieben | Bildquelle Fraunhofer IPT
Damit Projekte priorisiert werden können, muss eingeschätzt werden, ob die entsprechende Datengrundlage ausreicht. Dies ist möglich, wenn sich das Projektteam interdisziplinär zusammensetzt und die Mitarbeiter Expertise im Bereich Data Science aufgebaut haben. Neben theoretischem Wissen sollten die beteiligten Mitarbeiter bereits Erfahrungen mit dem Einsatz von ML mit konkreten Datensätzen mitbringen.
Freie Datensätze zum Üben
Dass vielen Mitarbeitern die Erfahrung im Umgang mit KI und ML fehlt hat zur Folge, dass trotz steigender Datenmengen die überwiegende Zahl an ML-Projekten scheitert. Ein Grund für den Mangel an praktischer Erfahrung ist, dass unternehmensinterne Daten unstrukturiert vorliegen, nicht die relevanten Informationen enthalten oder in nicht ausreichender Menge gespeichert werden. In diesen Fällen ist es jedoch möglich, mithilfe von frei verfügbaren Datensätzen erste Erfahrungen beim Einsatz von ML zu sammeln. Allerdings sind die im Bereich der Produktion öffentlich zugänglichen Datensätze auf unterschiedlichen Plattformen gespeichert.
Aus diesen Gründen wurden am Fraunhofer IPT öffentlich verfügbare Datensätze zum Sammeln erster Erfahrungen mit dem Fokus „Produktion“ eruiert. Diese Datensätze können den oben benannten sieben Anwendungsgebieten zugeordnet werden. Die gesamte Übersicht kann über den Link ipt.fraunhofer.de/ml-and-ai-in-production abgerufen werden, ein Auszug ist in Abbildung 2 dargestellt.

Abbildung 2: Auszug aus öffentlich verfügbaren Datensätzen mit dem Fokus auf Produktion und der Zuordnung zu ML-Anwendungsgebieten | Bildquelle: Fraunhofer IPT
Umsetzung allein oder mit Unterstützung
Ist das Anwendungsgebiet erst einmal festgelegt und sind die erforderlichen Erfahrungen gesammelt, kommt eine weitere Herausforderung auf das Unternehmen zu, denn die Prozesse und Produkte, bei denen die KI-Systeme zum Einsatz kommen, müssen zertifiziert werden. Die eingeschränkte Erklärbarkeit von ML-Modellen wird zu einem Umdenken in der Zertifizierung führen und wird vom Fraunhofer IPT sowie der Fraunhofer-Allianz Big Data AI aktiv mitgestaltet.
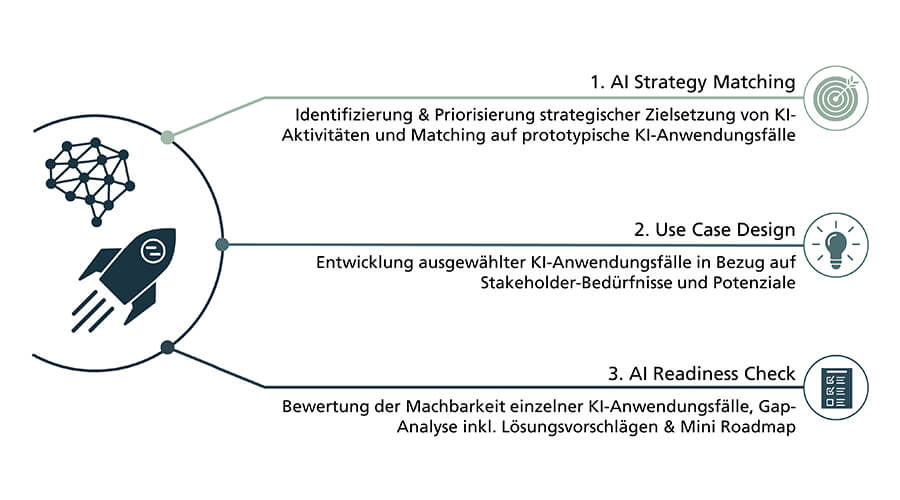
Zusammenfassend lässt sich feststellen, dass die zwei größten Hindernisse für Unternehmen derzeit darin liegen, die aussichtsreichsten KJI-Use-Cases zu identifizieren und die entsprechende Datengrundlage realistisch einzuschätzen. Daher sollten Unternehmen zuallererst in den Aufbau der eigenen Expertise investieren. Darüber hinaus ist es jedoch auch denkbar, die ersten Schritte auf dem Weg zum KI-Projekt gemeinsam mit externen Partnern zu machen. Das im Rahmen der Fraunhofer-Allianz Big Data AI entwickelte Angebot „AI Kick-Starter“ (siehe Abbildung 3) unterstützt Unternehmen darin, ihre Use Cases zielgerichtet zu bewerten und zu priorisieren.
Beitragsbild/Abbildung 3: Kick-Starter Bundle der Fraunhofer Allianz Big Data AI | Bildquelle: Fraunhofer IPT
Mehr Informationen
Sammlung von Anwendungsgebieten
ipt.fraunhofer.de/ml-and-ai-in-production
Ansprechpartner
Werkzeugmaschinenlabor WZL
RWTH Aachen
Prof. Robert H. Schmitt
Mitglied des Direktoriums
Tel.: +49 241 80-20283
E-Mail: R.Schmitt@wzl.rwth-aachen.de
Fraunhofer-Institut für Produktionstechnologie IPT, Aachen
Thomas Vollmer
Abteilungsleiter Produktionsqualität
Tel.: +49 241 8904-332
E-Mail: thomas.vollmer@ipt.fraunhofer.de
Jonathan Krauß
Gruppenleiter Process Optimization
Tel.: +49 241 8904-475
E-Mail: jonathan.krauss@ipt.fraunhofer.de
Schulung in digitalem Shopfloor Management als Teilgebiet der KI Mehr Informationen zu Artificial Intelligence